职场交流


df

帖子:7
精华:0
积分:14
注册:2022-04-07
对近十年后端架构发展的思考
回顾最近十年,我认为后端系统架构变化最大的有两点:一是以分布式系统为基础的微服务,另一个就是基于轻量级虚拟化的容器技术。本文以个人的技术项目经历为视角来看待这两个技术的发展背景,以及对背后原因的思考。
分布式系统需要解决的问题
2006年,我在百度负责一个音乐社区的开发,预计每日PV在500-1000W左右,这对于当时全国网民只有1.23亿的情况下,已经算是大流量了,放在今天也不算小了。百度是搜索引擎起家,核心技术栈是C/C++,而我当时基于开发效率和性能的综合考虑,选择的是Java语言。很多前辈提出忠告,让我小心性能问题。我针对典型场景分别用Java和C语言写了核心逻辑的实现,处理时间Java : C是6 : 1 ,即Java语言慢了6倍(随着编译优化技术的发展,今天已经没有这么大的差距了)。这个结果没有左右我的决定,我采用了分布式设计来解决面临的性能问题。架构示意图如图1所示。
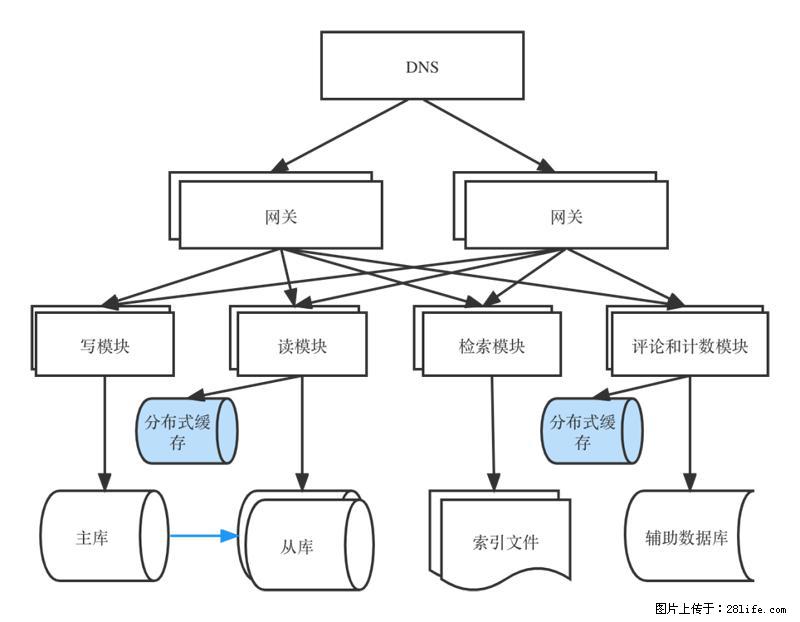
图1
从今天的视角看上去,这是一个平淡无奇的系统架构。但在2006年,业界的Java后端普遍还是单体应用的情况下,这已经是一个与众不同的系统了,跟今天的微服务看上去已经非常类似了,当时距离2014年微服务概念的提出还有8年。
当时服务器的配置基本上是双核(好的机器有4核)+4G内存,如果按照设计目标为500 QPS的话,经过测试单机肯定是扛不住的,因此必须由多台机器来承担。因此,要设计成分布式系统而不是单机,一个重要的原因是单机的性能有限,必须要多台机器来承担计算任务。
从业务角度来看,社区的功能操作,比如创建专辑(歌单)与检索,以及评论等,以上不同功能相对独立,可以由不同的人来开发,因此可以设计成不同的模块让团队更好地分工。因此,设计成分布式系统还可以让团队成员更好地协同工作。
但分布式系统带来的问题也很明显,引入多台机器后,需要解决的问题包括:负载均衡、容错处理、下游模块发现(后来叫服务发现)、分布式缓存数据一致性、主从数据库切换、系统扩容等分布式系统所带来的额外工作。
上面这些工作都靠我和同事们摸索着设计和开发,以及借鉴更为成熟的搜索引擎系统架构。比如定义模块之间的协议和调用方式、容错处理机制、模块更新时的处理机制、全局日志跟踪机制等。
这个音乐社区2006年正式上线,成为了百度第一个基于Java的日PV过百万的系统。也很荣幸能在我的主导下设计完成。
随着百度内部分布式架构越来越多,把与业务无关的公共组件抽取出来的需求也提上了议程。比如负载均衡组件的标准化、注册中心的提出与实现、通信协议的标准化等,让系统变得更加稳定的同时,也降低了开发分布式系统的难度。
微服务 - 分布式系统的一种标准化
由于分布式系统太复杂,对于什么是微服务并没有一个统一的定义。可以理解为微服务是一种分布式系统的设计风格。基本上可以通过把我上面设计的系统,对分布式部分进行标准化处理后而得到。我举几个例子:
1. 把每一个模块都设计成能独立运行的进程,为其他模块提供服务。这个过程叫组件化和服务化,再通过一套明确的通信机制来实现,比如RPC、或HTTP。
2. 组件的划分原则可以根据业务功能来,即每个组件实现一个逻辑上相对独立的(子)业务。
3. 各组件分散治理,不同业务组件保证自己的稳定性,组件之间通过接口约定通信即可。
4. 容错处理机制,每个组件都要有容错处理机制,假定系统和其他组件是不稳定的。
5. 数据分散管理,在业务允许的情况下通过最终一致性来保障系统的性能。
以上都是我在写本文时临时都能想到的点,其他就不再试图完整列举了。有一个原则想要提一下:如果在设计单体应用时假定的是组件不能出问题,那设计微服务是一定要假定组件会出问题,只是概率问题,这有设计的系统更加符合客观事实,只有按这样的思路设计系统,才能在系统层面保持良好的稳定性。如果把一个生物看做一个系统的话,单个细胞会死去,但不影响生物体还活着。
后来百度内部演化出了BRPC,广泛应用于C/C++和Java语言,后来开源出来了。Google有了gRPC,阿里开放了Dubbo,Netflix贡献了Zuul等,微服务的框架组件越来越丰富,微服务的概念也更加清晰了。因此,我认为微服务是业界总结、进化和沉淀出来的一套分布式系统设计风格。权衡了分布式系统带来的好处和复杂性。是分布式系统发展到一定阶段的产物,不是哪家公司或哪个人所发明的。
分布式系统的运维难题
2008年,百度的服务器已经以万为单位来计算,业务数量也暴增,比如除了网页搜索之外,还有图片搜索、新闻搜索、MP3搜索等垂直搜索,还有知道、贴吧、百科、百度空间等创新社区,此外商业方面还有广告系统,还在探索新的电商业务等等,服务模块早已成千上万,给系统的运维带来了巨大的挑战。比如上线一个版本时,需要所有涉及到的研发和运维同学在场,通过脚本来更新上千台服务器。要确保每个模块都正常更新和运行是一个巨大的挑战。公司高层意识到了运维方面的问题,发起了自动化运维的项目,由我来负责1.0版本的总体设计,这个项目的代号就是后来每个百度工程师都在使用的运维系统Noah。
时隔多年,细节已经不记得了,但依然还记得我设计系统时面临的几个主要挑战:上万台不同时期、不同配置、不同用途的服务器,如何确保对部署模块运行环境的兼容性、模块的正确依赖、运行库的正确依赖。
首先百度的服务器基本是x86架构,因此在机器指令层面的兼容性问题不大;再上层的操作系统都是Linux,所以操作系统层面的兼容性问题也不大。但更上层的依赖库就存在问题了,比如一些文本处理库、图像处理库、数据库客户端等库依赖,很多服务器都不一致了,再更上层的运行环境,包括配置文件、环境变量、文件系统权限、数据库地址等,就很难保障都是正确的了。我当时考虑过的方案之一是拿一台样板机,更新好最新的服务后做成镜像,然后克隆到其他服务器,但问题是这种方案太重了,有时候只需要更新很小的一个模块,没必要把整台服务器都重整一遍,并且不同的服务器需要设置成不同的配置,也需要额外有一套“调度系统”才能实现,因此放弃了这个想法。就这样,最初的方案与镜像技术擦肩而过。我当时通过结构化“服务归属与依赖关系图”实现了Noah 1.0版本,运维系统对依赖关系图的正确性要求很高。
巧妙的容器技术
百度运维所面临的问题是当时头部互联网公司的典型代表,其他公司也面临着同样的问题,包括太平洋对岸的Google。这些公司对镜像技术的需求已经很明显了,要是当年有一个轻量级的虚拟化技术,可以把一个服务模块运行在一个隔离的空间,最好这个空间不太重,最好就是一个进程加上一些特殊的配置,最好还不耗费操作系统资源,最好看起来还像一台单独的服务器...,其实这就是5年后以Docker为代表的容器。
Docker所需要的基础技术其实早就有了,比如隔离文件的chroot是1979年Unix 7提供的,隔离访问的Namespace是2002年Linux Kernel 2.4.19引入的,隔离资源的cgroups是2006年由Google发起后,在2008年Linux Kernel 2.6.24对外发布的,2016年Facebook的工程师又写了一个cgroups在4.5版本中。就如同组成我们人类细胞的物质与地球一样古老,存在了几十亿年,但却到了最近几万年才进化成人类一样,Docker也与之类似。并且容器设计的最初目的是为了隔离资源,但遇到了分布式服务的部署问题之后,尤其是云计算的服务商有强烈的自动化部署需求,在大量需求的推动下,容器的应用产生了本质的变化,迅速往服务部署的方向进化。图2展示了Docker与传统重量级虚拟机的对比,其实这个图还不够精确,Docker engine应该作为旁路才对。如此轻量级的虚拟技术,正是大家一直在寻找的梦寐以求的理想容器。
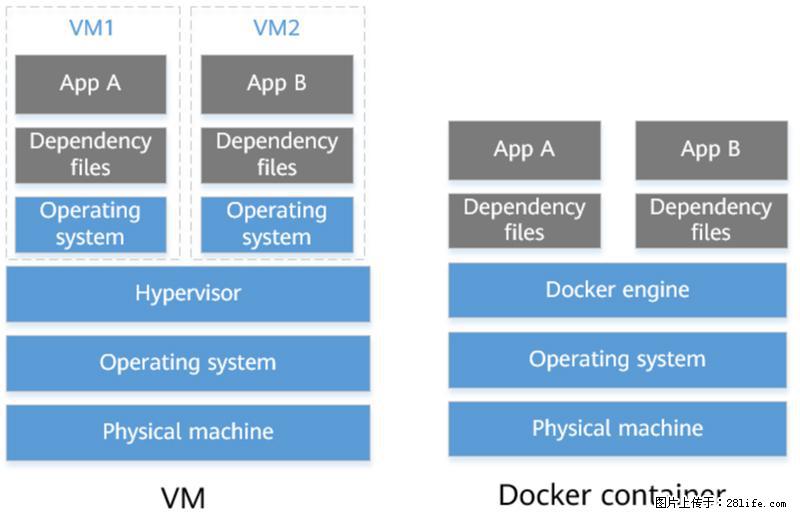
图2
基于容器化来部署分布式系统的思路,很好地解决了前面提到的大型互联网公司在自动化运维方面的痛点,因此在此基础上发展出来的容器化编排技术得到了长足发展和广泛应用。Kubernetes就是Google将他们内部的解决方案重写之后的开源版本。最近几年,网易各事业部也先后引入了K8S等技术将后端服务容器化,提高了运维效率和服务器的利用率。
最后再来总结一下:
1、由于互联网用户规模的增长,单台服务器的计算性能满足不了需求,要用多台服务器来协同完成,因此引入了分布式系统,解决的是机器性能容量的问题。
2、系统的分布式设计需要考虑团队分工,系统也需要通过标准化来提高效率,因此产生了微服务的概念。可以理解为生产力的发展促进了生产关系的变化。
3、容器技术解决了微服务化后带来的运维难题。
下一次后端架构的飞跃也许会在IOT时代。
2022年7月17日晚
本文转载自:蒋能学的技术笔记 https://mp.weixin.qq.com/s/TXo51w2CAedyyikzFwNFBg

查看移动版
← 扫码查看移动版【转发给朋友】或【分享到朋友圈】
1、查看方法:使用手机微信扫描二维码,打开本页移动端页面。
2、分享方法:在打开的本页移动端页面,点击右上角的“...”,选择【转发给朋友】或【分享到朋友圈】即可。
2、分享方法:在打开的本页移动端页面,点击右上角的“...”,选择【转发给朋友】或【分享到朋友圈】即可。

关注公众号
